Measuring Entropy Reduction: How much reduction in the entropy of X can we obtain by knowing Y?
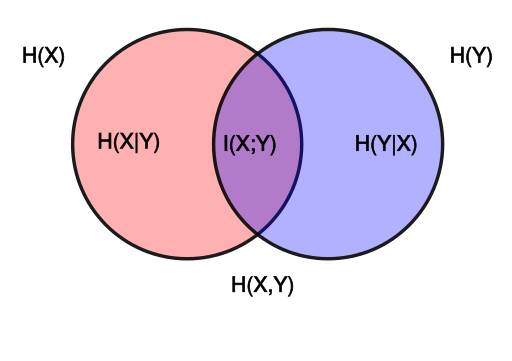
Properties
- symmetric
- non-negative
- I(X;Y)=0 iff X and Y are independent
Formally:
Expressed by KL Divergence:
MI measures the divergence of the actual joint distribution from the expected distribution under the independence assumption.
Furthermore,
Thus, MI can also be understood as the expectation of the Kullback–Leibler divergence of the univariate distribution p(x) of X from the conditional distribution p(x|y) of X given Y: the more different the distributions p(x|y) and p(x) are on average, the greater the information gain.
Reference
Mutual Information: https://en.wikipedia.org/wiki/Mutual_information
Text Mining: https://www.coursera.org/learn/text-mining